An Introduction to Multiprocessor Systems
How to Handle Writes
The first and easiest decision for a system designer is how to handle writes to shared data, there are two options: write-update and write-invalidate. Write-invalidate protocols require that when a CPU writes to a cache line, the writing CPU must notify sharing CPUs (i.e. other CPUs with that cache line) that their data for that cache line is now invalid and should not be used. This entails sending out the cache line address, which is relatively short, plus a few bits to indicate that it needs to be invalidated. Under a write-update protocol, the writing CPU updates any sharing CPUs by sending out the new value for the cache line, rather than simply sending out an invalidation message, so the messages are quite a bit larger. For example, in a 4 socket system, sending out a cache line update could take 64-128B, while an invalidate message would likely take around 5-8B. These numbers depend a bit on the virtual addressing capability, cache line size, and message protocol, but a 8-25x difference is still huge. There are currently no shipping high performance server systems that use write update because the bandwidth use is far too high, consequently all further discussions assume write invalidate.
Hops Enough for All
Another key differentiator between coherency protocols is the number of logical hops or stages in a transaction. Most protocols are either two or three hops. In a three hop protocol, the different phases are: request, snoop/forward and response. When a requesting processor misses in its cache, it first sends a query to the home node. Next, the home node snoops the rest of the system and reads the requested cache line from memory. Last, the home node and all processors in the system respond to the request and send data or an acknowledgement back to the original requester. The key to note is that the requesting processor cannot actually use any data until it has received messages from all other processors in the system. In a two hop coherency protocol, the first stage is simply omitted. The requesting processor snoops the entire system and then waits for responses. In general, two hop protocols have lower latency than three hop protocols, but the latter are better suited to directories. The animations in Figure 3 show the difference between the two. The top animation is a two hop coherency protocol, while the bottom shows a three hop protocol.
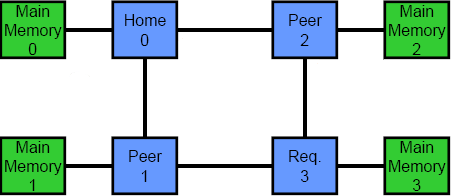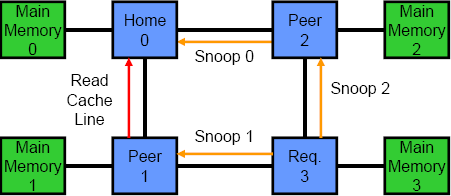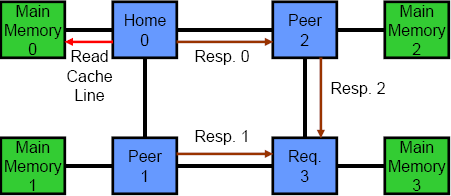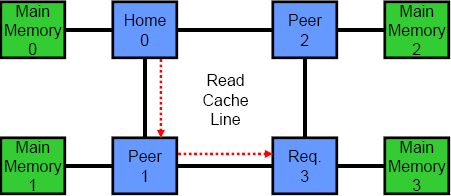
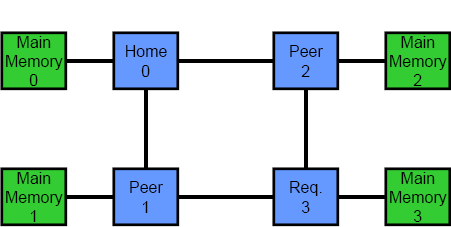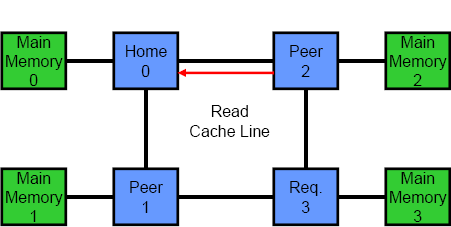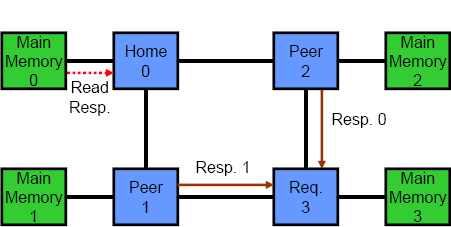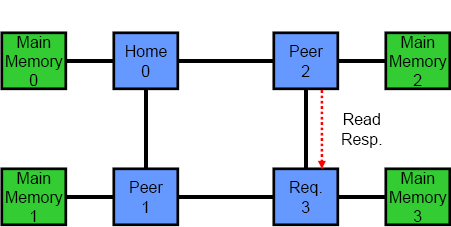
Figure 3 Two and Three Hop Coherency Protocols
Example Protocols
When a processor reads or writes a cache line, it must broadcast a snoop request to all other processors in the system to ensure that it gets the most recent valid cache line. When a processor wishes to write to a cache line, it must first broadcast an invalidate snoop, which tells other processors to evict that cache line. In both cases, the processor must wait to receive responses from all other processors before proceeding. Since all old copies of the cache line get evicted, there is no risk of a processor mistakenly using incorrect data. The two protocols used for x86 microprocessors are MESI (Intel: x86 and IPF) and MOESI (AMD). MESI is a two hop protocol and every cache line is held in one of four states, which track meta data, such as whether the data is shared or has been modified (i.e. is dirty):
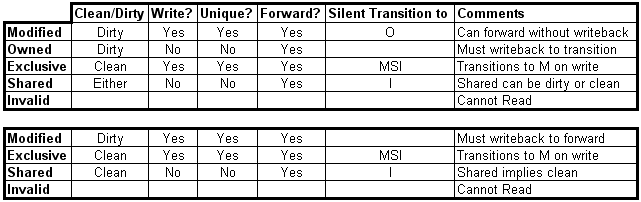
Chart 1 MOESI and MESI States
In contrast, MOESI is a three hop protocol with slightly modified states. Under MOESI, a processor can write to a line in the cache, and then put it in the O state and share the data, without writing the cache line back to memory (i.e. it allows for sharing dirty data). This can be advantageous, particularly for multi-core processors that do not share the last level of cache. For the MESI protocol, this would require an additional write back to main memory.
<< Prev Page