There are two different types of shared memory multi-processor systems: Symmetric Multi-Processors (SMPs) and Distributed Shared Memory (DSM). In both cases every processor can read and write to any portion of the systems memory. However, in an SMP system there is usually a single pool of memory, which is equally fast for all processors, (this is sometimes referred to as a Uniform Memory Access). In contrast, in a DSM system there are multiple pools of memory and the latency to access memory depends on the relative position of the processor and memory (this is also referred to as cache coherent Non-Uniform Memory Access). Typically, each processor has local memory (the lowest latency) while everything else is classified as remote memory and is slower to access.
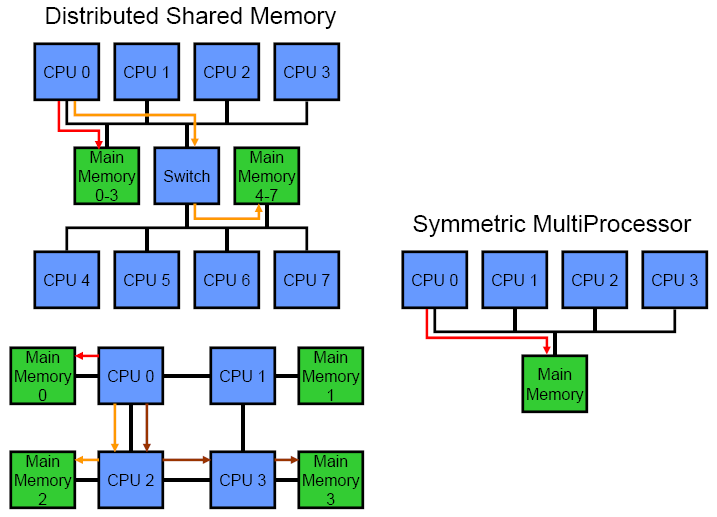
Figure 1 shows a 4P SMP and two 4P distributed systems for comparison, the arrows indicate the distance to each pool of memory. Note that the depicted DSM system can be divided into 4 different pools of memory and the associated processors. Each of these is called a node, and consists of exactly one pool of memory, and all the processors that are local to that memory; obviously, a node can have many processors. The node where data is stored in memory is referred to as the home node, while other nodes are described as remote or peers.
SMP systems nicely complement shared bus based architectures, since a shared bus provides a single point of arbitration, so cache coherency is relatively straight forward. When a processor needs to broadcast a cache coherency message, it simply sends that information over the bus, and all other processors can receive it. However, since memory is accessed at the speed of the slowest/most distant processor, physical limitations limit scalability to relatively few processors. This is the model that Intel has pursued since the advent of the Pentium Pro, and continues today with the entire Xeon line.
DSM systems scale more effectively because local memory can be accessed rapidly. Point to point interconnects are a natural fit for DSM, because the bandwidth grows proportionally to the number of processors and amount of memory in the system. The most common example of a DSM system is any 2 or 4 processor Opteron. However, most high-end systems such as IBMs pSeries, the HP Superdome, SGI Altix, or larger Sun and Fujitsu SPARC systems use distributed memory.
The biggest downside of distributed memory is that they only work well if the operating system is NUMA-aware and can efficiently place memory and processes. In particular, the OS scheduler and memory allocator play a vital role. Ideally, an intelligent OS would place data and schedule processes such that each process only accesses local memory and never needs remote data. For proprietary operating systems such as VMS, AIX, HP-UX or Solaris, incorporating such support is not particularly difficult. However, Windows is infamous for lacking effective NUMA support. Windows Server 2003 is the first version to offer any NUMA optimizations, but these require a fair bit of fiddling to enable. Fortunately, Windows Vista will improve on prior generations and will be the first version to have full support for NUMA optimizations.
Just as an aside, the distinction between system topologies is more subtle than SMP versus DSM. Within DSM, there are a variety of different topologies that can be used: crossbar, fat tree, torus, ring, hypercube, etc. Moreover, these topologies can be combined into hybrid topologies: a tree of rings, a crossbar of meshes, etc. For example, Figure 1 above shows a system that uses a direct connection between two nodes and each node is 4 processors on a shared bus. The topology plays a substantial role in determining the average latency and available bandwidth for a given system, which in turn determines the scalability. More importantly, different interconnect topologies have different implementation costs and benefits. While a detailed discussion is beyond the scope of this article, it is an important element to keep in mind.